Google's Speech-to-Text API features and reviews
Speech-to-text technology has made significant strides in recent years, and it has become an essential tool for many applications, from virtual assistants to automated customer service systems. Speech-to-text technology has revolutionized the way we interact with machines, making it possible to communicate with them in a more natural and intuitive way.
In this era of digital transformation, speech-to-text technology is increasingly being used in various industries to improve efficiency, productivity, and accessibility. Google Cloud Platform (GCP) offers a powerful suite of tools and services for speech-to-text technology that enables businesses to extract valuable insights from audio data quickly and efficiently. With its advanced algorithms, machine learning models, and natural language processing capabilities, GCP's speech-to-text technology is helping organizations streamline processes, improve customer experience, and drive innovation.
Pros and Cons of Google Speech to Text API:
Pros:
Increased efficiency and productivity: Speech-to-text tech boosts productivity by reducing typing and saving time.
Improved accessibility: Speech-to-text tech improves accessibility for individuals with typing challenges or disabilities.
Enhanced customer experience: Speech-to-text tech enhances the customer experience by enabling faster responses to inquiries and feedback.
Cost savings: Speech-to-text technology can automate transcription tasks, saving businesses significant costs on manual transcription.
Improved accuracy: Advanced speech-to-text technology offers high accuracy through ML models and NLP algorithms, minimizing manual review.
Improved collaboration: Speech-to-text tech improves collaboration by enabling real-time sharing of transcripts, notes, or messages among team members.
Increased speed of documentation: Speech-to-text technology boosts documentation speed by capturing meetings or conversations in real time.
Cons:
Accuracy issues: Speech-to-text tech accuracy may struggle in noisy/complex environments.
Language barriers: Speech-to-text tech may struggle with dialects, accents & languages beyond its programming.
Training requirements: Speech-to-text implementation requires substantial training & resources for optimal functioning.
We have added a GitHub repository link in the end, on how we overcame these technical challenges programmatically.
How is Speech-to-Text Technology Solving the Challenge of Converting Spoken Language to Written Text for our Clients?
Accurate speech transcription is important in modern business, enabling effective communication with customers, partners, and employees. Yet, the time-consuming and labor-intensive task of transcribing lengthy recordings can result in errors and inaccuracies, posing a major challenge for businesses today.
Automated speech-to-text conversion is a viable solution when manual transcribing is impractical due to resource limitations. Automated speech-to-text conversion can increase transcription efficiency, reducing time and labor costs while enabling companies to allocate resources to other tasks. It can easily scale to handle large volumes of audio files, making it ideal for high-volume information transcriptions.
Moreover, it can support multiple languages, cultural factors, and dialects making it suitable for global companies that need to transcribe information in different languages.
Finally, by analyzing the text produced by the speech-to-text conversion technology, companies can extract valuable insights from audio files, identifying trends, patterns, and important information that enables companies to make well-aware decisions.
Understanding the Recognition methods in Google speech-to-text
There are three recognition methods available with the Google Speech-to-Text API as said earlier.
Synchronous: (REST and gRPC) services use Speech to Text API for audio data recognition, limited to processing audio duration of one minute or less.
Asynchronous: (Rest and gRPC) services use asynchronous requests to initiate a Long Running Operation for audio data of any duration up to 480 minutes with the Speech-to-Text API.
Streaming Recognition: (gRPC only) It's designed for real-time recognition such as capturing audio from the microphone.
For one of our clients, we had to utilize an Asynchronous and Streaming Recognition Method which was required to transcript the call recordings and transcript the live calls for legal purposes.
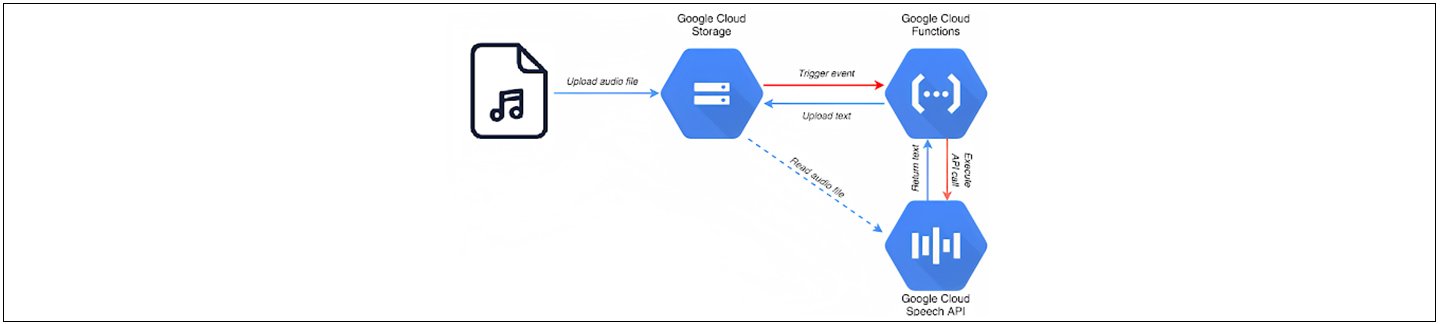
Reference Architecture Diagram:

We have added a GitHub repository link at the end of this document, which contains python programs to demonstrate all the above three recognition methods.
As said earlier there are some cons while using Speech-to-Text API which we overcame by using the error control mechanism of Google Cloud Speech API’s python module which provides several methods and functions through which we can set speech context, custom vocabulary, set boost values for specific words, control word error rate, provide built-in training model and by providing larger dataset for training.
Google's API Speech-to-Text implements a range of techniques to improve accuracy and reduce errors. We've discussed some of these error control mechanisms :
Custom Vocabulary: Adding custom words improves speech recognition accuracy and recognizes industry-specific jargon or uncommon words.
Control Word Error Rate (WER): WER is a speech recognition accuracy metric that can be used to minimize errors and improve accuracy by setting a target value.
Language Model and Speaker Adaptation: Adapting the language model to a specific domain improves accuracy, and speaker adaptation reduces errors caused by variations in voice.
Confidence Scores: Confidence scores measure the accuracy of the system's recognition and low scores can trigger re-recognition or prompt users to repeat the phrase.
Error Correction: Error correction can fix mistakes after they're made, like spell check or contextual correction.
Multi-pass Recognition: Multi-pass recognition processes speech data multiple times with different models to improve accuracy and reduce errors.
Diarization: Diarization is audio speaker separation to improve transcription accuracy by identifying who spoke when.
Noise Reduction and Adaptive Beamforming: Noise reduction algorithms improve audio quality by filtering out background noise, while adaptive beamforming focuses microphone arrays on specific sounds and suppresses noise.
Pronunciation and Grammar Models: Google's speech recognition improves accuracy by analyzing language patterns across languages/dialects using pronunciation & grammar models.
Language Detection: Google's speech recognition can detect spoken language and adjust its models, improving accuracy for multilingual speech and language switching.
Word-Level Confidence Scores: Google's speech recognition can detect spoken language and adjust its models, improving accuracy for multilingual speech and language switching.
Speech-to-Text API ensures accurate transcriptions through these advanced error control mechanisms including custom vocabularies, language model adaptation, speaker recognition, and noise reduction.
Conclusion
In conclusion, speech-to-text technology with GCP provides an innovative solution that can enhance the efficiency and productivity of businesses, while also making digital communication more accessible for individuals. With advanced machine learning models and natural language processing algorithms, GCP's speech-to-text technology can achieve high levels of accuracy, reduce transcription costs, and improve customer service interactions. However, it is essential to note that there may be potential limitations and challenges, such as accuracy issues, language diversity, and privacy concerns, that require careful consideration during implementation. Overall, GCP's speech-to-text technology presents an exciting opportunity for businesses to leverage the power of machine learning and automation to streamline communication processes, reduce costs, and enhance customer experiences.
GitHub Repository link